For many creative teams, the early excitement of text-to-video generation eventually hits a wall. That wall is usually the “generative gamble”. The reality is that typing a prompt and hoping for a specific camera movement is rarely a wise strategy.
This is why it’s important to establish a structural anchor that creates a reliable output in generative media that mostly depends on “kinetic intent”. It’s a practice of developing a static source image so that the motion engine within Banana AI comprehends its depth clearly before a frame is rendered.
This article explains how you should treat an image as a blueprint rather than a final product, through which content teams can transition from random motion to definitive storytelling outputs.
Key Takeaways
- Professional workflows must create detailed prompts to obtain a result that is best aligned with what they had in mind in the first place
- High-contrast edges help the model understand where the “object” ends and the “environment” begins
- If the source image is structurally sound, the kinetic transition becomes a matter of fine-tuning rather than troubleshooting
- Despite the advancements in models like Nano Banana, there are clear technical boundaries that creators must respect to avoid wasted render credits and lost time
When we move from text-to-video to image-to-video, we are effectively providing the model with a set of “latent physics.” In a text-to-video scenario, the model has to generate both the subject and the motion simultaneously, which often leads to physical hallucinations—limbs morphing into background objects or horizons shifting unnaturally.
By beginning with a high-quality static image, the creator provides a fixed reference point. The model no longer has to guess what the subject looks like. It only has to define how that subject would displace pixels over time.
For professional workflows, that is the key difference between a clip that looks perfect and a sequence that looks like filmed footage.
The key to success with the Nano Banana motion logic is understanding how the model interprets depth. If an image has clear foreground, midground, and background separation, the motion engine can accurately simulate parallax.
Without these cues, the motion often feels “flat,” as if the entire image is being stretched or warped rather than moving through a three-dimensional space.
Preparation begins long before the “Generate” button is clicked. Using a dedicated AI Image Editor is essential for setting the stage. A common mistake is using a raw AI-generated image that is cluttered with “visual noise”—unnecessary textures or blurry edges that the motion model might interpret as motion vectors.
To optimize a static source for motion, creators should focus on three primary anchors:
In the Banana Pro ecosystem, the goal of pre-production is to create a “clean” map. If the source image is structurally sound, the kinetic transition becomes a matter of fine-tuning rather than troubleshooting.
Not all motion models are built for the same purpose. Within the production environment, creators often have to choose between different engines depending on the desired momentum of the asset.
Nano Banana Pro is generally optimized for cinematic, structured movement. It excels at controlled camera pans, slow-motion character movements, and maintaining the “weight” of objects. If you are creating a product showcase or a narrative scene where the subject must remain recognizable and grounded, this is the preferred engine. It prioritizes temporal consistency—the ability of a pixel to remain “itself” from frame one to frame sixty.
In contrast, models like Seedance 2.0 are often used for more fluid or high-velocity transformations.
Seedance allows for a more creative “drift”, which is impressive for abstract visuals, liquid simulations, or fast-paced transitions where the exact geometry of the subject is less important than the actual flow.
Choosing between such things is a strategic decision: do you need the scene to hold together under judgment, or do you need it to move with maximum energy?
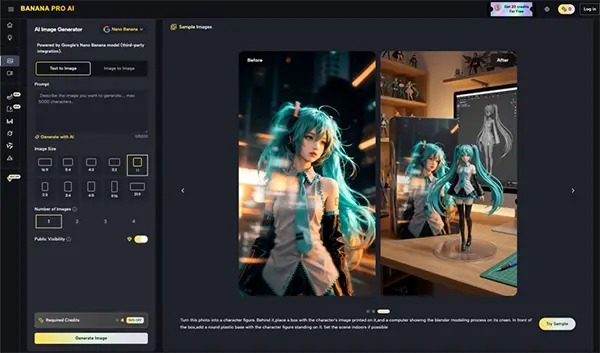
The workflow is rarely linear. In a professional setting, the first video output is often a diagnostic tool. By observing where the motion fails—perhaps a hand disappears into a pocket, or a background tree starts to “grow”—the creator can return to the static image to fix the underlying cause.
The “First Frame” strategy is particularly effective here. Using the generative fill tools in an image editor, a creator can expand the workspace of the source image. For example, if you want a wide camera pan to the left, you shouldn’t start with a cropped image. You should outpaint the image to the left, providing the video engine with the data it needs to “reveal” the new scenery.
During the image-to-video transition, negative prompting remains a vital, if underutilized, tool. While text-to-video users use negative prompts to avoid “ugly” faces, I2V users use them to suppress specific types of motion failures, such as “morphing,” “blurring,” or “flicker.” This allows the Nano Banana engine to focus its computational power on the intended motion vectors.
Despite the advancements in models like Nano Banana, there are clear technical boundaries that creators must respect to avoid wasted render credits and lost time.
First, maintaining fine-grain text or specific logos during a significant camera move remains a major challenge. If a character is wearing a shirt with a specific brand name and performs a 180-degree turn, the model will almost certainly “hallucinate” the text into gibberish halfway through the turn.
Current latent logic is excellent at tracking shapes, but it does not “read” text in a way that preserves its semantic meaning across temporal shifts.
Second, there is a significant level of uncertainty when handling overlapping motion. For instance, a character walking through heavy rain or a crowd.
The model often struggles to differentiate between the motion of the foreground subject and the overall “noise” of the environment. In such cases, the subject may end up accidentally absorbing the motion of the rain, leading to jittery movement or distorted silhouettes.
Finally, complex physics involving transparency and refraction, such as water being poured into a glass or light passing through a prism, remain experimental, as these interactions need a level of physical simulation that most generative models assume rather than calculate.
Expecting hundred percent accuracy in such scenarios is unrealistic. They often require multiple experiments or post-production masking to appear professional.
Fun Fact
Generating high-quality footage reduces video creation time from weeks of setup, shooting, and editing to just a few minutes of processing.
The ultimate goal for content teams is to move away from “one-off” cool clips and toward a repeatable production line. This requires building a library of “high-potential” static images—assets that have been specifically designed with their eventual motion in mind.
By standardizing the pre-production stage, using consistent depth mapping, lighting angles, and resolutions, teams can make sure that their video outputs retain a uniform look and feel. This is essential for multi-shot sequences where the lighting in clip A must match the lighting in clip B.
Kinetic intent is the bridge between casual experimentation and professional media production. When you stop asking the AI to “make something move” and start instructing it “how to move this specific object,” the quality of the output changes significantly.
As models continue to evolve, the creators who master the art of static “blueprint” are the ones who define the standard of AI-native cinematography.
Ultimately, the power of tools like Banana Pro lies not in their ability to generate random pixels but in their ability to respond to precise, intentional creative direction.